 |
| Unload Db2 data to remote client |
Showing posts with label data in action. Show all posts
Showing posts with label data in action. Show all posts
Thursday, February 6, 2025
Db2: Loading and unloading of data on remote clients with external tables
Friday, January 17, 2025
Once again: Db2 External Tables
 |
| Db2 log files and data on IBM COS |
Wednesday, August 28, 2024
A look at local external tables in Db2
 |
| Surprising Db2 results or not? |
Tuesday, July 16, 2024
About BIRD, SQL, IBM granite models, and your business reporting
 |
| BIRD-SQL benchmark |
Tuesday, February 20, 2024
Spreadsheets: How to excel with Db2 data
 |
| Generated chart in Excel file |
Wednesday, November 22, 2023
Unicode string length, code points, and Db2
 |
| Byte length of (Unicode) strings |
Friday, November 25, 2022
Finally together: Db2 and Zeppelin
 |
| United: Db2 and Zeppelin |
Tuesday, September 6, 2022
New IBM Cloud security features you should know
 |
| Custom role for operating Code Engine |
Wednesday, November 24, 2021
Rate-limit Kafka event generation with kcat and bash
 |
| Traffic for event streams |
Thursday, November 18, 2021
On serverless data scraping, cloud object storage, MinIO and rclone
 |
| Building a data lake the serverless way |
Monday, May 18, 2020
Some advanced SQL to analyze COVID-19 data
 |
| Learn to write SQL |
Monday, January 27, 2020
25th meeting of German Db2 User Group
 |
| Celebrating the 25th DeDUG meeting |
Tuesday, May 7, 2019
Cloud-based FIPS 140-2 Level 4 crypto service
 |
| Locks, keys, and data security |
Wednesday, April 24, 2019
Updated tutorial: Database-driven chatbot
If you want to build a chatbot that gets its content from a database, there is a good news. The existing tutorial “Build a database-driven Slackbot”
was just updated to adapt to latest features of IBM Watson Assistant.
First, define a skill that reaches out to a database service like Db2.
Thereafter, use the built-in integrations to easily tie in the assistant
with Slack, Facebook Messenger, embed the chatbot into your
own application or use the WordPress plugin.
 |
| Architecture of database-driven chatbot |
Monday, October 22, 2018
Automated reports with IBM Cloud Functions, Db2 and Slack
 |
| GitHub Traffic Analytics |
Tuesday, June 26, 2018
Enable Botkit Middleware for Watson Assistant for serverless actions
 |
| Slack chatbot with Watson Assistant |
Tuesday, June 19, 2018
DeDUG-Treffen in Ehningen / Db2 User Group meeting near Stuttgart
 |
| Db2 User Group Meeting |
This time you have the opportunity to learn more about the SQL explain facility, query optimization, SQL recursion and several other topics. Similarly to the previous event, we are going to have lightning talks again. They are short, 3-8 minute talks in which YOU can present a solution, introduce a technical problem for which you are looking for a solution, or tell us your best database-related joke or an anecdote.
You can register through several channels:
- ARS: https://web.ars.de/dedug2018_19_ehningen/
- ids-System: https://www.ids-system.de/leistung/schulungen/9-dedug/502-19-treffen-der-deutschen-db2-user-group-dedug-am-29-06-2018-in-ehningen
- Meetup: https://www.meetup.com/de-DE/DeDUG-RUG/
See you at the DeDUG meeting at IBM Germany in Ehningen. If you have feedback, suggestions, or questions about this post, please reach out to me on Twitter (@data_henrik) or LinkedIn.
Monday, April 23, 2018
Use Db2 and IBM Cloud to analyze GitHub traffic data (tutorial)
 |
| Architecture: GitHub Traffic Analytics |
Monday, February 19, 2018
New tutorial: Db2-driven Slackbot
Ever wanted to build a Slackbot, a chatbot integrated into Slack, on your own? I am going to show you how easy it is to integrate Slack or Facebook Messenger with the IBM Watson Conversation service.
As a bonus, the bot is going to access a Db2 database to store and
retrieve data. The solution is based on IBM Cloud Functions and entirely serverless
.
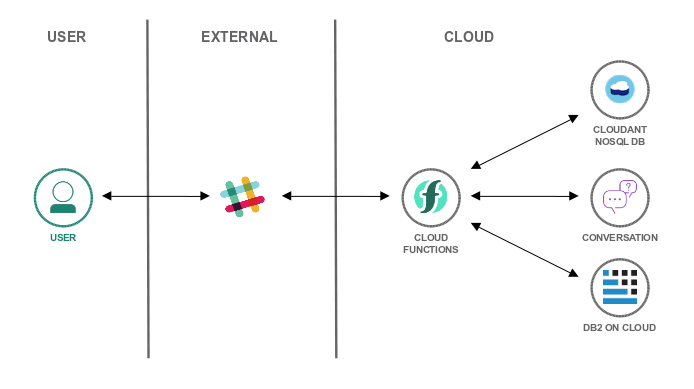 |
| Slackbot Architecture |
Tuesday, February 6, 2018
Chatbots: Some tricks with slots in IBM Watson Conversation
 As you might remember, I have been using the IBM Watson Conversation service and DB2. My goal was to write a database-driven Slackbot, a Slack app that serves as chat interface to data stored in Db2. I will write more about that entire Slackbot soon, but today I wanted to share some chatbot tricks I learned. How to gather input data, perform checks and clean up the processing environment.
As you might remember, I have been using the IBM Watson Conversation service and DB2. My goal was to write a database-driven Slackbot, a Slack app that serves as chat interface to data stored in Db2. I will write more about that entire Slackbot soon, but today I wanted to share some chatbot tricks I learned. How to gather input data, perform checks and clean up the processing environment.Slots
With my chatbot interface to Db2 I want to both query the database and insert new records. Thus, I need to collect input data of various kind. The Conversation service has a neat feature named input slots that simplifies that process. Within a dialog node (a logical step within the chat flow) I can specify a list of items the Conversation service should check for. I can tell in which variable to save that input and what question to ask if that data was not provided yet. Optional slots, i.e., optional data, can be enabled.
Subscribe to:
Posts (Atom)