Last Friday I was on the way back from some customer visits. While traveling in a German highspeed train I used the Wifi service, connected to IBM Bluemix and created a DB2 in-memory database. Let me show you how I set it up, what you can do with it and how I am connecting to the cloud-based database from my laptop.
Sitting in #train with 300 km/h and creating #DB2 in-memory #database with #Bluemix http://t.co/OzJqLzNDFr
— Henrik Loeser (@data_henrik) August 22, 2014
 |
| Unbound DB2 service on Bluemix |
The console supports several administration and development tasks as show in the picture. It includes loading data, to develop analytic scripts in R, to execute queries and link the data with Microsoft Excel for processing in a spreadsheet, and it has a section to connect external tools or applications to the database.
 |
| Administration/development task in DB2 BLU console on Bluemix |
Great! You can even import #JSON #data from @Cloudant into #DB2 in-memory db service in #Bluemix pic.twitter.com/BoLS0YM7nH
— Henrik Loeser (@data_henrik) August 22, 2014
You can set up replication from a Cloudant JSON database to DB2, so that the data stream is directly fed in for in-memory analyses. I didn't test it so far, but plan to do so with one of my other Bluemix projects.
A task that I used is to (up)load data. For this I took some historic weather data (planning ahead for a vacation location), let the load wizard extract the metadata to create a suitable data, and ran some queries.
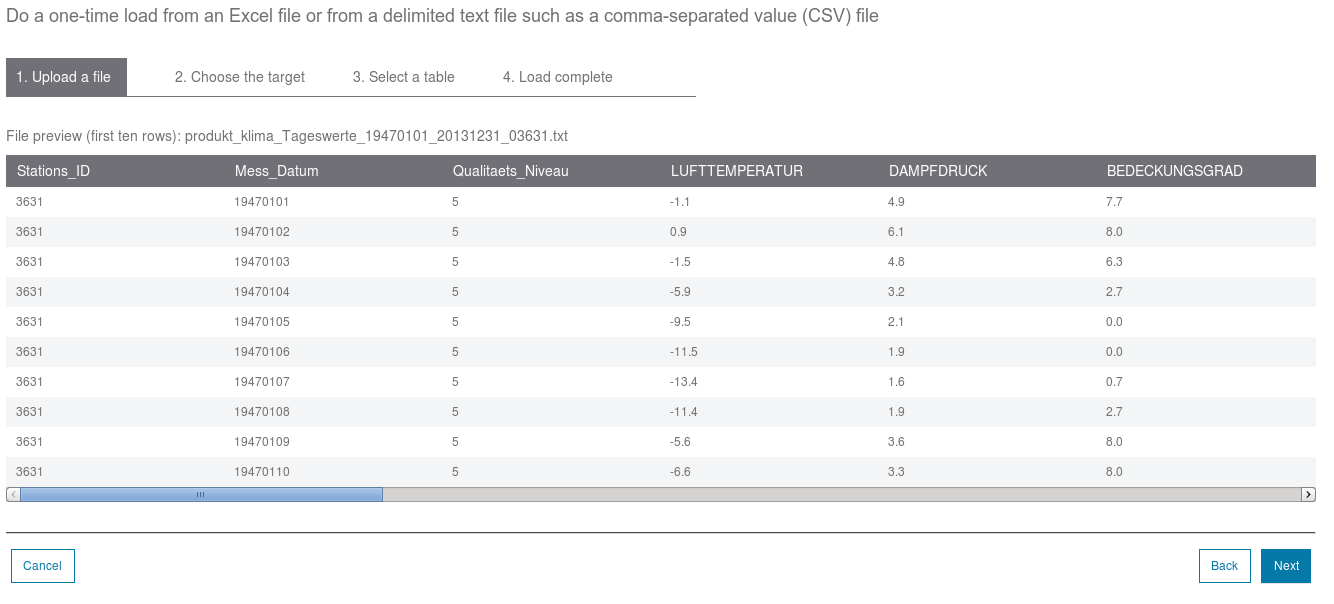 |
| Uploading data to DB2 on Bluemix |
 |
| Specify new DB2 table and column names |
For executing (simple) selects there is a "Run Query" dialogue. It allows to choose a table and columns and then generates a basic query skeleton. I looked into whether a specific German island had warm nights, i.e., a daily minimum temperature of over 20 degrees Celsius. Only 14 days out of several decades and thousands of data points qualified.

Last but not least, I connected my local DB2 installation and tools to the Bluemix/Softlayer-based instance. The "CATALOG TCPIP NODE" is needed t make the remote server and communication port known. Then the database is added. If you already have a database with the same name cataloged on the local system, it will give an error message as shown below. You can work around it by specifying an alias. So instead of calling the database BLUDB, I used BLUDB2. The final step was to connect to DB2 with BLU Acceleration in the cloud. And surprise, it uses a fixpack version that officially is not available yet for download...
DB: => catalog tcpip node bluemix remote 50.97.xx.xxx server 50000
DB20000I The CATALOG TCPIP NODE command completed successfully.
DB21056W Directory changes may not be effective until the directory cache is
refreshed.
DB: => catalog db bludb at node bluemix
SQL1005N The database alias "bludb" already exists in either the local
database directory or system database directory.
DB: => catalog db bludb as bludb2 at node bluemix
DB20000I The CATALOG DATABASE command completed successfully.
DB21056W Directory changes may not be effective until the directory cache is
refreshed.
DB: => connect to bludb2 user blu01xxx
Enter current password for blu01xxx:
Database Connection Information
Database server = DB2/LINUXX8664 10.5.4
SQL authorization ID = BLU01xxx
Local database alias = BLUDB2
I will plan to develop a simple application using the DB2 in-memory database (BLU Acceleration / Analytics Warehouse) and then write about it. Until then read more about IBM Bluemix in my other related blog entries.