 |
| Job in Delivery Pipeline to rotate keys |
Showing posts with label Cloudant. Show all posts
Showing posts with label Cloudant. Show all posts
Thursday, August 1, 2019
Use a Delivery Pipeline to rotate credentials
Friday, September 14, 2018
Tutorial on how to apply end to end security to a cloud application

Did you ever wonder how different security services work together to secure a cloud application? In the new tutorial we use
- IBM Cloud Activity Tracker to log all security-related events. This includes logging in to the account, provisioning or deleting services, working with encryption keys and more.
- IBM Cloud Key Protect to manage encryption keys. For the tutorial, we generate a root key for envelope encryption of stored files. You could also import your own root key (bring your own key, BYOK). We use the root key to create encrypted buckets in the IBM Cloud Object Storage service.
- IBM Cloud Object Storage (COS) service to produce expiring links to individual files. The links can be shared with others and expire after the set amount of time, so that the file cannot be accessed thereafter.
- IBM Cloud App ID as a wrapper around (enterprise and social) Identity Providers to manage authentication and authorization through a single interface. The App ID service can be directly integrated with Kubernetes Ingress.
- IBM Cloud Container Registry as a private image registry from which we deploy the application as container into a Kubernetes cluster (IBM Cloud Kubernetes Service). The container registry includes a Vulnerability Advisors that scans for and assesses container vulnerability and then recommends fixes.
If you have feedback, suggestions, or questions about this post, please reach out to me on Twitter (@data_henrik) or LinkedIn.
Thursday, May 24, 2018
How to pack serverless Python actions
 |
| Serverless access to Db2 and GitHub |
Monday, February 19, 2018
New tutorial: Db2-driven Slackbot
Ever wanted to build a Slackbot, a chatbot integrated into Slack, on your own? I am going to show you how easy it is to integrate Slack or Facebook Messenger with the IBM Watson Conversation service.
As a bonus, the bot is going to access a Db2 database to store and
retrieve data. The solution is based on IBM Cloud Functions and entirely serverless
.
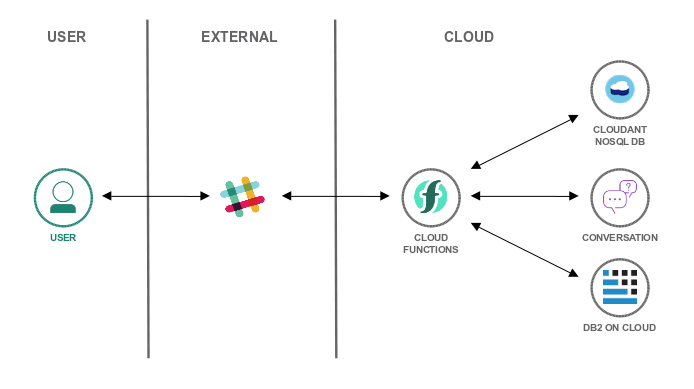 |
| Slackbot Architecture |
Friday, September 29, 2017
App Security Scanner: My Cloud Database App is Secure
 |
| Cloud Application Security |
Monday, March 20, 2017
IBM Bluemix in Germany, includes dashDB and Cloudant
 |
| IBM Bluemix in Germany, in German |
Having Bluemix Public in Germany is a big step for the IBM Cloud and customers alike. Being located next to DE-CIX means low network latency for German and European customers. Utilizing Bluemix Public in London ("eu-gb") it is possible to deploy applications with high-availability requirements redundantly within Europe. The database-as-a-service offerings dashDB ("DB2") and Cloudant are already available in the Bluemix catalog. More database and analytics services are to follow. You can check out the list of initial services here in the Bluemix Catalog for Germany.
That's all for today. I am back to MY German Bluemix...
Friday, February 24, 2017
Securing Workloads on IBM Cloud - Some Resources
 |
| Security Guides for IBM Cloud |
Friday, February 3, 2017
Security and Compliance for IBM dashDB and Cloudant
 |
| Database Security & Compliance |
Monday, August 22, 2016
Notes on Notebooks, Data, DB2, and Bluemix
 |
| Weather Graph in Jupyter Notebook |
If you can't wait until then I recommend to take a look at these recent blog posts on how to get started with Notebooks and data on Bluemix:
- The first blog gives you basics on processing data in so-called data frames and to generate tables and graphs. The data is Open Data and is loaded off the Analytics Exchange on Bluemix. The notebook utilizes the computing power of an Apache Spark cluster.
- The second blog covers how to analyze Twitter data for market trends. The example uses dashDB/DB2 to hold the data. The scripts are written in Python and plug into Sentiment Analysis and Natural Language Processing to understand tweets.
- The last in my list for today is a blog on how to use Apache Spark GraphFrames in notebooks. Airports and flight routes between them are used as base for some computations. It is something every (business) traveler understands.
That's it for today with my notes on notebooks.
Monday, April 11, 2016
Data Protection, Privacy, Security and the Cloud
 |
| Protecting your bits |
(This is the first post in a planned series on data protection, security, and privacy related to DB2/dashDB in the cloud and IBM Bluemix)
As a data/database guy from Germany, security and data protection and privacy have been high on my list of interests for many, many years. As a banking customer I would hate it when someone not authorized would access my data. I also don't like to go through the hassle of replacing credit cards, changing passwords, take up a new name (user name only :), or more because a system my data is or was on had been hacked. With more and more data being processed "in the cloud" it is great to know how much effort has been put into designing secure cloud computing platforms, into operating them according to highest security standards, and how international and local data protection standards and laws are followed for legal compliance.
Friday, April 1, 2016
New Bluemix Data Sink Service Tackles Data Overload

Initially the experimental Bluemix service is free and allows to pipe up to 1 TB (one terabyte) of data a month to the data sink. Customers already on direct network links will be able to utilize the full network bandwith. This gives the opportunity to test the DSaaSTR offer for the following scenarios:
- The abundance of sensors and their generated data, whether in Internet of Things (IoT) or Industry 4.0 scenarios, leaves companies struggling with data storage. Utilizing the new service they can leverage the DSaaSTR in the cloud to get rid of local data.
- The more data and data storage options, the more intruders. By piping data to the Bluemix DSaaSTR it will become unavailable for attackers.
- Local data archives require active data management, enforcement of retention policies, and rigorous disposal. DSaaSTR offers easy choices for data retention and disposal.
- Many enterprises have learned that even Hadoop Clusters need actively managed storage. DSaaSTR can be configured to be part of a local or cloud-based Hadoop system (hybrid cloud), thus eliminating storage costs and simplifying the overall administration tasks for the cluster.
Wednesday, March 16, 2016
CeBIT: Goldsmith in the Hybrid Cloud - How to Create Value from Enterprise Data
 |
| Gold Nuggets - Data as Gold |
Thursday, February 18, 2016
Building a Solution? The Cloud Architecture Center has Blueprints
 |
| Cloud Architecture Center |
Right now the IBM developerWorks Cloud Architecture Center features an architecture gallery where you can filter the available blueprints by overall area like data & analytics, Internet of Things (IoT), Mobile or Web Application. Another filter criterias are by industry or capability, i.e., you could look for sample solution for the insurance industry or a use-case featuring a Hybrid Cloud scenario.
 |
| Partial view: Architecture for Cloud Solution |
For the selected architecture and solution you are presented with the overall blueprint (as partially shown in the screenshot) and are offered information about the flow, the included components are deployed services and products, and get an overview of the functional and non-functional requirements. Depending on the solution there are links to sample applications, code repositories on GitHub, and more reading material. See the Personality Insights as a good example.
The Architecture Center offers great material for enterprise architects and solution designers and the linked samples and demos are also a good start for developers.
(Update 2016-02-21): There is a new and good overview article with focus on Big Data in the cloud and possible architecture.
Monday, August 24, 2015
Keeping track of "my" DB2
 Some years back when talking about DB2, there was only the "I am on the host" or "We are mostly OLTP" distinction. My standard phrase has been "I am a distributed guy". Well, today, when only talking about DB2 for Linux, UNIX, and Windows ("DB2 LUW"), some more description is needed to clearly state what, where, and how the product is used. Here is a small overview of my world of DB2 LUW.
Some years back when talking about DB2, there was only the "I am on the host" or "We are mostly OLTP" distinction. My standard phrase has been "I am a distributed guy". Well, today, when only talking about DB2 for Linux, UNIX, and Windows ("DB2 LUW"), some more description is needed to clearly state what, where, and how the product is used. Here is a small overview of my world of DB2 LUW.- The regular, well-known DB2 for Linux, UNIX, and Windows that can be used on your laptop or your cluster of high-end servers in your data center ("on premise" or "on-prem") is available in seven different editions. Depending on the edition it features database encryption, highly efficient data compression, scalability for OLTP and analytic workloads (and others :), BLU Acceleration technology, federation support, and much more. Currently, DB2 is at version 10.5 with fix pack 6 being out since a week.
- If you are interested in using the Advanced Workgroup Server Edition or other editions of DB2 and don't want to deal with setup and maintenance, you could use the DB2 on Cloud service offered on IBM Bluemix (more cloud-based hosting options for DB2 are described in this overview).
- A fully provisioned version of DB2 is available as so-called SQLDB service on Bluemix. It helps you get started in no time and serves as relational data store for your apps on Bluemix.
- When it comes to cloud-based data warehousing and analytics, dashDB is the way to go. Its technology is based on DB2 with BLU Acceleration and Netezza. dashDB shares a lot of DB2, but not the Knowledge Center which dashDB has on its own... dashDB can be provisioned either through IBM Bluemix or through the NoSQL database Cloudant.
- The query language SQL is popular for accessing the data dumped into the Big Data lake/pond/reservoir/swamp. The IBM product BigInsights to manage and process Big Data features Big SQL for that task and is making use of DB2's proven technology. And as before, you can use BigInsights on Bluemix.
If you have not done so, I would recommend taking a look at the IBM Data Server Manager as fairly new tool to monitor, administrate, and tune DB2. The experience in using the web-based GUI can directly be applied to the administration interfaces of the related DB2 services in the cloud, sqldb and dashDB.
Monday, July 20, 2015
Bluemix: Simple cron-like service for my Python code
 |
| Schedule background tasks in Bluemix |
The trick is in the file manifest.yml and the Cloudfoundry documentation has all the needed details (Bluemix is built on this open standard). The attribute "no-route" is set to true, indicating that this is not a Web application and we don't need a subdomain name. In addition the attribute "command" is set to invoke the Python interpreter with my script as parameter. Basically, this starts my background task:
applications:
- name: hltimer
memory: 256M
instances: 1
no-route: true
command: python mytimer.py
path: . The cron-like service script is pretty simple. It uses the "schedule" package to set up recurring jobs. I tested it with the Twilio API to send me SMS at given timestamps. You can also use it to scrape webpages in given intervals, kick off feed aggregators, read out sensors and update databases like Cloudant or DB2, and more. See this Github repository for the full source.
import schedule
import time
def job():
#put the task to execute here
def anotherJob():
#another task can be defined here
schedule.every(10).minutes.do(job)
schedule.every().day.at("10:30").do(anotherJob)
while True:
schedule.run_pending()
time.sleep(1) Tuesday, April 21, 2015
My 10 Minute DB2 App on Bluemix
I needed some fun at the end of the workday today. Why not enhance my own skills, do some "coding", and try out Node-RED on Bluemix again (I performed a "phoney" test in October already). This time, I wanted to see whether a database like DB2 or dashDB is supported as backend.
To get started I logged into my free trial account on http://bluemix.net. I selected the "Node-RED Starter" from the catalog and created the app skeleton. After the app was staged (the resources allocated, files copied, and the skeleton app started), I could begin wiring up my application logic. My first look on the wiring board went to the list of supported storage nodes. What was new since my last test is support for dashDB and "sqldb" (DB2) as input and output nodes. That is, it is possible to store data in those two database systems (output) and bring data into the app by querying a database (input).
To use DB2 in Node-RED, you need to create a sqldb service in Bluemix first. This meant going back to the catalog, skipping to the Data Management section, selecting the sqldb service, and adding it to my application (see picture below). Thereafter, my application needed to be restaged (restarted), so that it could pick up the properties of the sqldb service.
| Node-RED Starter |
 |
| Node-RED storage nodes |
To use DB2 in Node-RED, you need to create a sqldb service in Bluemix first. This meant going back to the catalog, skipping to the Data Management section, selecting the sqldb service, and adding it to my application (see picture below). Thereafter, my application needed to be restaged (restarted), so that it could pick up the properties of the sqldb service.
Monday, November 17, 2014
A quick look at dashDB and a happy SQuirreL
 |
| dashDB slogan on its website |
 |
| Cloudant Warehousing (dashDB) |
 |
| dashDB: schema discovery |
The welcome screen shows some of the analytic options, e.g., the database is ready to be used with either Cognos, SPSS, InfoSphere DataStage, R scripts, or all of them and more:
 |
| Analytis for dashDB: Cognos, SPSS, DataStage, R |
 |
| SQuirrel SQL client - dashDB connected |
My lessons learned from testing database queries on the converted data (JSON to relational) will be part of another blog entry. Stay tuned...
Monday, October 13, 2014
Node-RED: Simple "phoney" JSON entries in Cloudant
 |
| Node-RED Starter on IBM Bluemix |
The Node-RED boilerplate automatically creates a Node.js runtime environment on Bluemix and installs the Node-RED tool into it. In addition, a Cloudant JSON database is created. Once everything is deployed I opened the Node-RED tool in a Web browser. It offers a basic set of different input and output methods, processing nodes, and the ability to connect them in a flow graph. One of the input nodes is a listener for http requests. They help to react to Web service requests. I placed such http input node on the work sheet and labeled it "phone" (see screenshot).
 |
| Node-RED tool on Bluemix |
How did I obtain information about callers and the numbers they called?
What I needed now was the data processing flow of the Web services request. On Friday I already tweeted the entire flow:
Easy. Cool. #NodeRED used to store #caller info coming from #sipgate API into #Cloudant on #Bluemix pic.twitter.com/MFkqFAdp5D
— Henrik Loeser (@data_henrik) October 10, 2014
On the left we see "phone" node as http input. Connected to it is the "ok" node which sends an http response back, telling the phone company's Web services that we received the information. The other connected node is a "json" processor which translates the payload (who called which number) into a meaningful JSON object. That object is then moved on to the "calls" node, a Cloudant output node. All we needed was to select the Cloudant service on Bluemix and to configure the database name.
 |
| Cloudant Output Node, Node-RED on Bluemix |
 |
| "Phoney" record in Cloudant |
Monday, August 25, 2014
Setting up and using a DB2 in-memory database on IBM Bluemix
[Update 2014-11-04: The Analytics Warehouse service on Bluemix is now called dashDB.]
Last Friday I was on the way back from some customer visits. While traveling in a German highspeed train I used the Wifi service, connected to IBM Bluemix and created a DB2 in-memory database. Let me show you how I set it up, what you can do with it and how I am connecting to the cloud-based database from my laptop.
The first thing to know is that on Bluemix the DB2 in-memory database service is called IBM Analytics Warehouse. To create a database, you select "Add service" and leave it unbound if you want, i.e., it is not directly associated with any Bluemix application. That is ok because at this time we are only interested in the database. Once the service is added and the database itself created, you can lauch the administration console.
The console supports several administration and development tasks as show in the picture. It includes loading data, to develop analytic scripts in R, to execute queries and link the data with Microsoft Excel for processing in a spreadsheet, and it has a section to connect external tools or applications to the database.
One of the offered task is very interesting and I twittered about it on Friday, too:
You can set up replication from a Cloudant JSON database to DB2, so that the data stream is directly fed in for in-memory analyses. I didn't test it so far, but plan to do so with one of my other Bluemix projects.
A task that I used is to (up)load data. For this I took some historic weather data (planning ahead for a vacation location), let the load wizard extract the metadata to create a suitable data, and ran some queries.
For executing (simple) selects there is a "Run Query" dialogue. It allows to choose a table and columns and then generates a basic query skeleton. I looked into whether a specific German island had warm nights, i.e., a daily minimum temperature of over 20 degrees Celsius. Only 14 days out of several decades and thousands of data points qualified.

Last but not least, I connected my local DB2 installation and tools to the Bluemix/Softlayer-based instance. The "CATALOG TCPIP NODE" is needed t make the remote server and communication port known. Then the database is added. If you already have a database with the same name cataloged on the local system, it will give an error message as shown below. You can work around it by specifying an alias. So instead of calling the database BLUDB, I used BLUDB2. The final step was to connect to DB2 with BLU Acceleration in the cloud. And surprise, it uses a fixpack version that officially is not available yet for download...
DB: => catalog tcpip node bluemix remote 50.97.xx.xxx server 50000
DB20000I The CATALOG TCPIP NODE command completed successfully.
DB21056W Directory changes may not be effective until the directory cache is
refreshed.
DB: => catalog db bludb at node bluemix
SQL1005N The database alias "bludb" already exists in either the local
database directory or system database directory.
DB: => catalog db bludb as bludb2 at node bluemix
DB20000I The CATALOG DATABASE command completed successfully.
DB21056W Directory changes may not be effective until the directory cache is
refreshed.
DB: => connect to bludb2 user blu01xxx
Enter current password for blu01xxx:
Database Connection Information
Database server = DB2/LINUXX8664 10.5.4
SQL authorization ID = BLU01xxx
Local database alias = BLUDB2
I will plan to develop a simple application using the DB2 in-memory database (BLU Acceleration / Analytics Warehouse) and then write about it. Until then read more about IBM Bluemix in my other related blog entries.
Last Friday I was on the way back from some customer visits. While traveling in a German highspeed train I used the Wifi service, connected to IBM Bluemix and created a DB2 in-memory database. Let me show you how I set it up, what you can do with it and how I am connecting to the cloud-based database from my laptop.
Sitting in #train with 300 km/h and creating #DB2 in-memory #database with #Bluemix http://t.co/OzJqLzNDFr
— Henrik Loeser (@data_henrik) August 22, 2014
 |
| Unbound DB2 service on Bluemix |
The console supports several administration and development tasks as show in the picture. It includes loading data, to develop analytic scripts in R, to execute queries and link the data with Microsoft Excel for processing in a spreadsheet, and it has a section to connect external tools or applications to the database.
 |
| Administration/development task in DB2 BLU console on Bluemix |
Great! You can even import #JSON #data from @Cloudant into #DB2 in-memory db service in #Bluemix pic.twitter.com/BoLS0YM7nH
— Henrik Loeser (@data_henrik) August 22, 2014
You can set up replication from a Cloudant JSON database to DB2, so that the data stream is directly fed in for in-memory analyses. I didn't test it so far, but plan to do so with one of my other Bluemix projects.
A task that I used is to (up)load data. For this I took some historic weather data (planning ahead for a vacation location), let the load wizard extract the metadata to create a suitable data, and ran some queries.
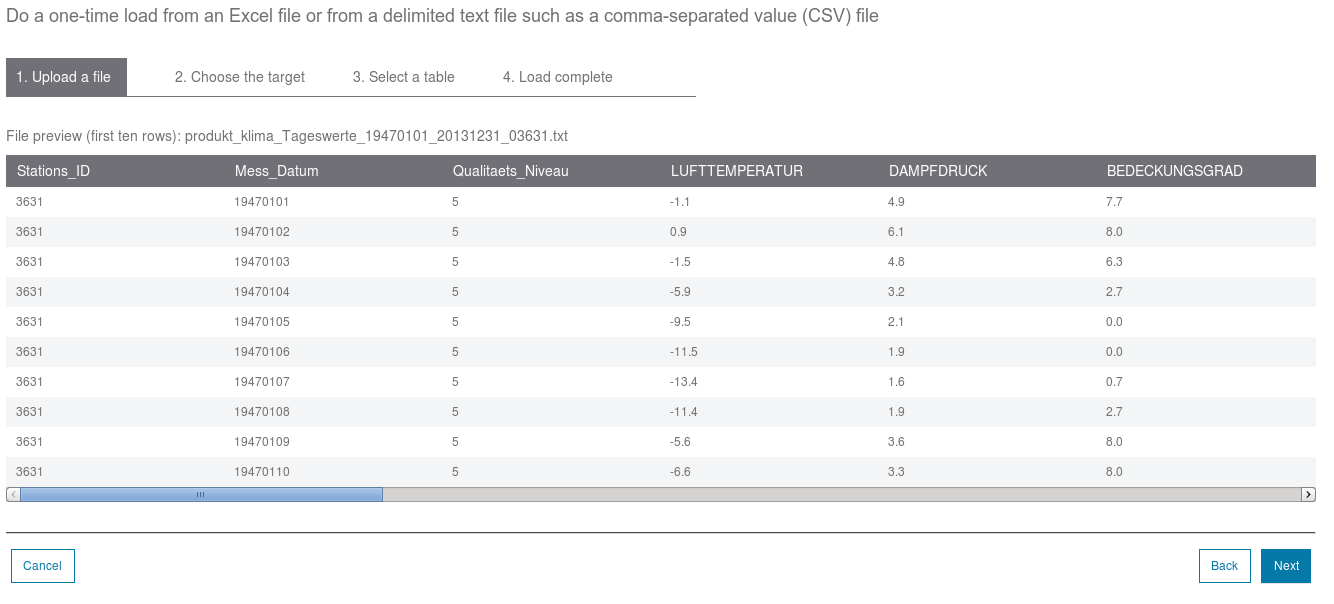 |
| Uploading data to DB2 on Bluemix |
 |
| Specify new DB2 table and column names |
For executing (simple) selects there is a "Run Query" dialogue. It allows to choose a table and columns and then generates a basic query skeleton. I looked into whether a specific German island had warm nights, i.e., a daily minimum temperature of over 20 degrees Celsius. Only 14 days out of several decades and thousands of data points qualified.
Last but not least, I connected my local DB2 installation and tools to the Bluemix/Softlayer-based instance. The "CATALOG TCPIP NODE" is needed t make the remote server and communication port known. Then the database is added. If you already have a database with the same name cataloged on the local system, it will give an error message as shown below. You can work around it by specifying an alias. So instead of calling the database BLUDB, I used BLUDB2. The final step was to connect to DB2 with BLU Acceleration in the cloud. And surprise, it uses a fixpack version that officially is not available yet for download...
DB: => catalog tcpip node bluemix remote 50.97.xx.xxx server 50000
DB20000I The CATALOG TCPIP NODE command completed successfully.
DB21056W Directory changes may not be effective until the directory cache is
refreshed.
DB: => catalog db bludb at node bluemix
SQL1005N The database alias "bludb" already exists in either the local
database directory or system database directory.
DB: => catalog db bludb as bludb2 at node bluemix
DB20000I The CATALOG DATABASE command completed successfully.
DB21056W Directory changes may not be effective until the directory cache is
refreshed.
DB: => connect to bludb2 user blu01xxx
Enter current password for blu01xxx:
Database Connection Information
Database server = DB2/LINUXX8664 10.5.4
SQL authorization ID = BLU01xxx
Local database alias = BLUDB2
I will plan to develop a simple application using the DB2 in-memory database (BLU Acceleration / Analytics Warehouse) and then write about it. Until then read more about IBM Bluemix in my other related blog entries.
Friday, July 25, 2014
The Hunt for the Chocolate Thief (Part 2) - Putting IBM Bluemix, Cloudant, and a Raspberry Pi to good use
I am still on the hunt for the mean chocolate thief, kind of. In the first part I covered the side of the Raspberry Pi and uploading data to Cloudant. I showed how to set up an infrared motion sensor and a webcam with the RPi, capture a snapshot and secure the image and related metadata in a Cloudant database on the IBM Bluemix Platform-as-a-service (PaaS) offering. In this part I am going to create a small reporting website with Python, hosted as a IBM Bluemix service.
Similar to an earlier weather project, I use Python as scripting language. On Bluemix, which is based on Cloud Foundry, this means to "bring your own buildpack". I already described the necessary steps which is to tell Bluemix how to create the runtime environment and install the needed Python libraries. So how do I access the incident data, i.e., the webcam snapshots taken by the Raspberry Pi when someone is in front of the infrared motion sensor? Let's take a look at the script:
The setup phase includes reading in access data for the Cloudant database server. Either that information is taken from a Bluemix environment variable or provided in a file "cloudant.json" (similar to what I did on the RPi). The main part of the script defines three routes, i.e., how to react to certain URL requests. The index page (index()) returns an overview of all recorded incidents, an incident detail page (incident(id)) fetches the data for a single event and embeds the stored webcam image into the generated page, and the last route (image(id)) redirects the request to Cloudant.
Looking at how the index page is generated, you will notice that a predefined Cloudant view (secondary index) named "incidents/incidents" is evaluated. It is a simple reduce function that sorts based on the timestamp and document ID and returns just that composite key.
function(doc) {
if (doc.type == "oc")
emit({"ts" : doc.timestamp, "id" : doc._id}, 1);
}
Then I access the timestamp information and generate the list as shown in the screenshot above.
The incident detail page has the document ID as parameter. This makes it simple to retrieve the entire document and print the details. The webcam image is embedded. So who got my chocolate? Take a look. It looks like someone who got a free copy of "Hadoop for Dummies" at the IDUG North America conference.
Maybe another incident will shed light into this mystery. Hmm, looks like someone associated to the "Freundeskreis zur Förderung des Zeppelin Museums e.V." in Friedrichshafen. I showed the pictures to my wife and she was pretty sure who took some chocolate. I should pay more attention when grabbing another piece of my chocolate and should more closely watch how much I am eating/enjoying.
Have a nice weekend (and remember to sign up for a free Bluemix account)!
Similar to an earlier weather project, I use Python as scripting language. On Bluemix, which is based on Cloud Foundry, this means to "bring your own buildpack". I already described the necessary steps which is to tell Bluemix how to create the runtime environment and install the needed Python libraries. So how do I access the incident data, i.e., the webcam snapshots taken by the Raspberry Pi when someone is in front of the infrared motion sensor? Let's take a look at the script:
import os
from flask import Flask,redirect
import urllib
import datetime
import json
import couchdb
app = Flask(__name__)
# couchDB/Cloudant-related global variables
couchInfo=''
couchServer=''
couch=''
#get service information if on Bluemix
if 'VCAP_SERVICES' in os.environ:
couchInfo = json.loads(os.environ['VCAP_SERVICES'])['cloudantNoSQLDB'][0]
couchServer = couchInfo["credentials"]["url"]
couch = couchdb.Server(couchServer)
#we are local
else:
with open("cloudant.json") as confFile:
couchInfo=json.load(confFile)['cloudantNoSQLDB'][0]
couchServer = couchInfo["credentials"]["url"]
couch = couchdb.Server(couchServer)
# access the database which was created separately
db = couch['officecam']
@app.route('/')
def index():
# build up result page
page='<title>Incidents</title>'
page +='<h1>Security Incidents</h1>'
# Gather information from database about which city was requested how many times
page += '<h3>Requests so far</h3>'
# We use an already created view
for row in db.view('incidents/incidents'):
page += 'Time: <a href="/https://blog.4loeser.net/incident/'+str(row.key["id"])+'">'+str(row.key["ts"])+'</a><br/>'
# finish the page structure and return it
return page
@app.route('/incident/<id>')
def incident(id):
# build up result page
page='<title>Incident Detail</title>'
page +='<h1>Security Incident Details</h1>'
doc=db.get(id)
# Gather information from database about the incident
page += '<br/>Incident at date/time:'+str(doc["timestamp"])
page += '<br/>reported by "'+doc["creater"]+'" at location "'+doc["location"]+'"'
page += '<br/>Photo taken:<br/><img src="/https://blog.4loeser.net/image/'+id+'" />'
# finish the page structure and return it
return page
@app.route('/image/<id>')
def image(id):
#redirecting the request to Cloudant for now, but should be hidden in the future
return redirect(couchServer+'/officecam/'+id+'/cam.jpg')
port = os.getenv('VCAP_APP_PORT', '5000')
if __name__ == "__main__":
app.run(host='0.0.0.0', port=int(port))  |
| Overview of Security Incidents |
Looking at how the index page is generated, you will notice that a predefined Cloudant view (secondary index) named "incidents/incidents" is evaluated. It is a simple reduce function that sorts based on the timestamp and document ID and returns just that composite key.
 |
| Incident Detail: Hadoop involved? |
if (doc.type == "oc")
emit({"ts" : doc.timestamp, "id" : doc._id}, 1);
}
The incident detail page has the document ID as parameter. This makes it simple to retrieve the entire document and print the details. The webcam image is embedded. So who got my chocolate? Take a look. It looks like someone who got a free copy of "Hadoop for Dummies" at the IDUG North America conference.
Maybe another incident will shed light into this mystery. Hmm, looks like someone associated to the "Freundeskreis zur Förderung des Zeppelin Museums e.V." in Friedrichshafen. I showed the pictures to my wife and she was pretty sure who took some chocolate. I should pay more attention when grabbing another piece of my chocolate and should more closely watch how much I am eating/enjoying.
 |
| Zeppelin Brief seen at robbery |
Have a nice weekend (and remember to sign up for a free Bluemix account)!
Subscribe to:
Posts (Atom)