🔊🔥:这个项目已经作废,移步到隔壁文件夹📁:https://github.com/yuanzhoulvpi2017/zero_nlp/tree/main/chinese_clip_ddp
- 本文将介绍,如何从0到1的训练一个中文clip模型。
- 在处理数据的过程中,训练的过程中,需要的注意事项。
- 从数据流的角度,看看clip模型是怎么处理数据的,模型是怎么构建的。image和text的模型的差异性,两个模型是怎么合并起来计算loss的。
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。
CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,
CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,
模型能够学习到文本-图像对的匹配关系。
如下图所示,CLIP包括两个模型:
- Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;
- Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
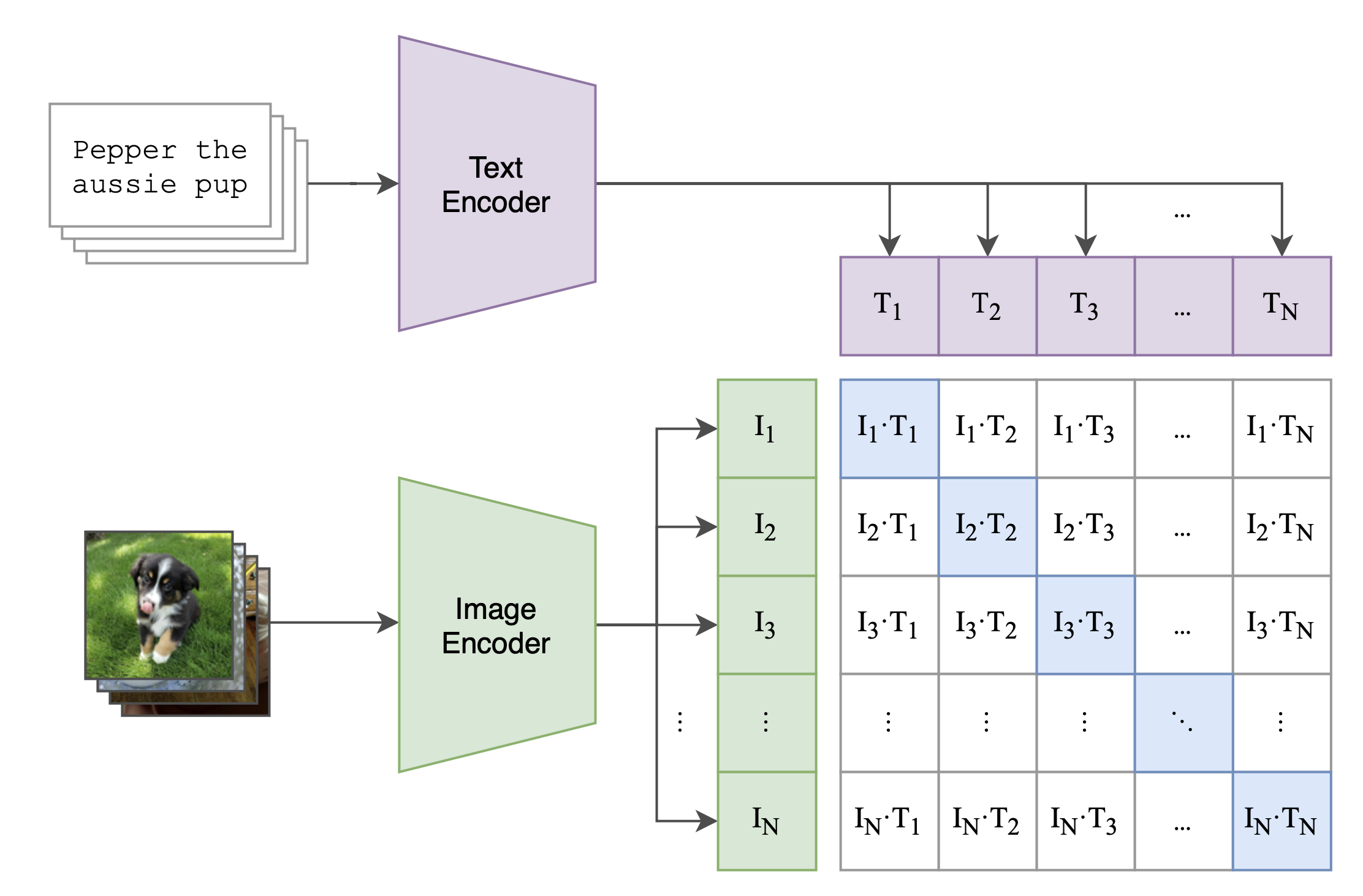

上面这段文字来源于https://zhuanlan.zhihu.com/p/493489688
- 从数据上看:之前相似度计算,都是两个文本对:
text - text。只不过现在都是text - image了。 - clip是两个模型(具体长什么样子,后面再说)
- 2.1
text-model:负责把text转换成向量。 - 2.2
image-model:负责把image转换成向量。 - 2.3 然后把上面两个向量,做交叉计算loss,然后loss反向传播,这样两个模型的参数都会更新。
- 其实你想啊,这个
image-model处理图像的,其实也可以改为处理视频、处理3d模型等。那简直是格局打开🫴了。我现在没有数据,后面也打算做一个。 - 你再想想,
text-image=>text-image-video-3d这样联合起来,是不是更好。没数据,没机器,做不了。 - 有些人可能感觉,
你这人,就知道TMD吹牛,来来来,我带你研究研究clip模型的源码。
计算机这行业就是这样,你文字写的天花乱坠,都不如直接去看看源码。因为看源码,可以帮你了解,这些数学算法到底是怎么实现的。
【待完善】
- 数据来源于公众号
YeungNLP,关注他,并且回复005即可获得。当然也可以直接点击链接https://pan.baidu.com/s/1wGmXUNP021OWnW7Kik7q1A?pwd=gd3c 来获得。 - 把下载好的文件,也就是
test-2.6w.csv、train-137w.csv放在文件夹📁bigdata/raw_data里面。 - 以此运行
processdta_01.ipynb、processdta_02.ipynb、processdta_02.ipynb用来处理数据。
- 3.1
processdta_01.ipynb:用来下载数据,大概下载了10多个小时。 - 3.2
processdta_02.ipynb:用来筛选数据,不是所有的图片数据都是可以用的,这一步非常坑。需要留意。如果图片没有筛选好,在你训练到中间的时候,突然一下因为图片无法加载导致错误,从而训练中断了。 - 3.3
processdta_03.ipynb:用来把数据干净的数据处理好,合并好,生成新的,漂亮的训练数据。
- 其实完整下来看,数据清洗,就是把符合格式的照片筛选出来,然后进行训练。
说到底,你的数据只要整理成这样的一个样式即可
| text | image_path |
|---|---|
| 河南一村民继承祖上的一金碗,专家鉴定:此碗是溥仪皇帝用过的 | bigdata/image_data/test-9282.jpg |
| 著名钢琴家郎朗:我永远不会放弃演奏 | bigdata/image_data/test-2644.jpg |
| 科幻动作电影《超体》10月24日来袭 | bigdata/image_data/test-13199.jpg |
text:这一列对应图片的标注,或者和图片相关的文本。image_path:这一列对应图片所在你电脑本地上的路径。- 是的,搞了半天,数据就是这么简单。
这里的数据预处理,是我随便起的名字。说白了,就是这么会是:
- 使用
tokenizer把text转换成input_ids和attention_mask. - 使用
processor把image转换成pixel_values.
- 处理
text,那还是很快的。百万级别的数据,可能2~3分钟就行了。 - 因为
image太大了,只能在训练的时候,每一batch,才能去加载image,这就导致训练的时候特别慢。倒不是因为我的3090算力不行,全都TMD卡在计算机IO上了,非常让人难受。
终于讲解到clip的模型部分了。这个clip模型实在是太灵活了,你可以做很多个版本,这里我们挑几个比较常见的结构,来分享一下。
这里值得是常见的clip模型,特指的是transformers包的clip模型。
- clip主要就是分为两个部分,一个是
CLIPTextTransformer,一个是CLIPVisionTransformer,说白了就是一个处理text,一个处理image。 CLIPTextTransformer和CLIPVisionTransformer的核心,都共用了一个模型结构CLIPEncoder。也就是CLIP编码部分。(这里说的共用,值得是模型框架相同,而不是模型训练的时候,参数也相同。)
Q:有些人就问了,text和image两个生成的数据都不一样,比如text转换成input_ids和attention_mask;image
转换成pixel_values;他们怎么可以使用一个模型结构CLIPEncoder?
A:这个也是非常好回答的,因他俩又不是直接使用CLIPEncoder
,前后都加了一些万金油的模型组件(比如embedding、linear
等),模型输出的时候,也是这么做的。还是应了那句话,就看你怎么吧数据转换成hidden_states,以及怎么把hidden_states输出出去。
Q:CLIPTextTransformer和CLIPVisionTransformer输出的维度也不一定一样吧,怎么计算交叉损失?
A: 也很简单啦,加个linear对齐一下就行了。


上面的常见的clip模型,确实是好,其实你只要换一个支持中文的新tokenizer,然后从0️⃣开始训练即可。
但是这么搞,没什么创意呀。其实我第一次就是这么干的,直接支持中文的新tokenizer。但是训练了一天,loss基本上没变化。我内心其实是崩溃的。
后来,我研究了一下transformers包里面的chinese-clip模型代码。我发现,chinese-clip相对于clip
。就是把常规的CLIPTextTransformer换成了bert版本的。啊对,这就破案了。这个奉上代码截图。

我以为这个换成这个模型也就可以了。但是训练了1天,loss依然没有变化。
这次训练clip其实还是非常失败的。
- 尝试了很多方法,但是模型的loss就是不下降,非常难受。
- 因为io问题,耽误训练进度,难受。
- 因为图片做的筛选不到位,返工几次,耽误我接近7~8小时,非常难受。
- 因为训练image这类型的任务,非常吃资源,不管是我的显存还是我的磁盘。目前数据占用我硬盘
100GB - 针对loss不下降,下次如果再让我做,我打算先把
clip模型的vit部分先固定住,然后训练bert来拟合vit-output。 - 也可也固定bert模型,训练vit模型;
- 也可以拆开做,反正本质上都是
Encoder,然后计算相似度。 - 如果那位同学有机器,有数据,有需求的话,可以联系我邮箱:📪yuanzhoulvpi@outlook.com 微信:🛰️yuanzhoulvpi_god